
I am currently working on a new database structure for data from the Mongoose Project (blog post to follow). Dave and I recently had a discussion about how best to get new data from the Mongoose in Uganda to the researchers here in the UK.
The current solution is an sqlite database that is created in the Raspberry pi and e-mailed from Uganda. This is suboptimal for a couple of reasons. It requires the manual step of sending an e-mail, meaning the data maybe months out of date. Also, there is no one 'truth' data source. Multiple copies can be worked on by multiple people and reconciling the changes is additional work and risks data loss.
The field site recently got mobile internet coverage, and data plans are inexpensive, meaning that we can have a real-time data connection and avoid these problems.
Things we don't know about
- exact way of setting up the network on their side so the ad hoc network connects the tablets, whilst an internet connection can be used to send data out to us. (update: We have prototyped this with a new pi v3 and it seems doable)
- simple way of adding to a queue from within scheme code.
- how to get non-tablet captured data into the system.
Things we would like
- get rid of the pi, and send data straight from the tablets to us in the UK.
- be able to update software without hassles (Android app update is simple, maybe Pi updates are harder - currently this means an SD card swap on the Pi).
- all data for the new database to be processed through the tablets.
- remove distinction between event types.
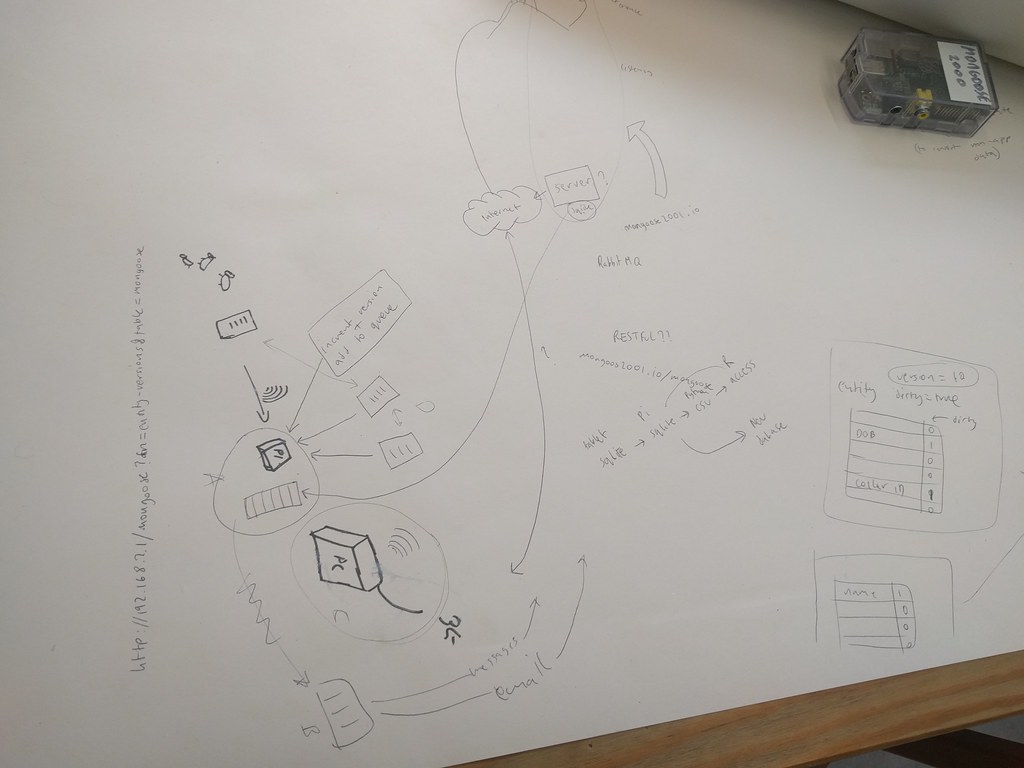
Option A
Post events onto the queue at the same point they are written to the sqlite database on the Pi. The events are published onto a rabbitmq queue.
A service running here (or on cloud) gathers the events and writes them to a database (possibly sqlite format in the short term, then postgres later)
All updates are sent with unique identifiers and duplicates are discarded by the service our side.
pros
- limits changes
- simple architecture
cons
- requires the Pi to exist
- networking complexity
- cannot update Pi software from here (or can we!?)
Option B
One tablet is given the option to upload data. This 'blessed' tablet connects to us (or the cloud) and sends new data to us. Simplest is an upload of the sqlite database in its entirety, or re-creating the events stream and publishing that to a queue.
pros
- similar to existing solution (sqlite db is currently e-mailed rather than auto uploaded)
- maybe allows events to be sent in a different format, more applicable to the new database schema
- similar to existing scheme, so maybe liked by some researchers
- can update tablet software easily
cons
- not so automatic - may require user to hit send. This adds complexity and potential for misunderstanding.
- what if multiple tablets become 'blessed' or the 'blessed' one breaks down. User education required.
- unsure of how to get things on the queue (maybe Java?)
- unsure if rabbitmq can exist on an android tablet. If not some other system may be required?
Option C
Install software on their pc to do the queue and send data to us.
pros
- easy to write new software (assuming windows machine)
- know we can run queues on desktops
cons
- we know nothing about the machine
- unable to manage it to our liking. cannot remotely update software.
- may interfere with their use of the computer
Option D
Each tablet connects to the wireless network in Uganda that has internet access. They all send their data to each other, and to a remote node.
pros
- removes Pi and is nice
cons
- complex (what if all tablets in Uganda break...)
- needs quite a bit of thinking about async processes to ensure every tablet is updated, and no data is lost.
- unsure about queues on tablets
- unsure about multiple connections out to internet. how do we ensure not too much data traffic, and that data is not overwritten.